随着深度学习的不断发展,AI模型结构在快速演化,底层计算硬件技术更是层出不穷,对于广大开发者来说不仅要考虑如何在复杂多变的场景下有效的将算力发挥出来,还要应对计算框架的持续迭代。深度编译器就成了应对以上问题广受关注的技术方向,让用户仅需专注于上层模型开发,降低手工优化性能的人力开发成本,进一步压榨硬件性能空间。阿里云机器学习PAI开源了业内较早投入实际业务应用的动态shape深度学习编译器 BladeDISC,本文将详解 BladeDISC的设计原理和应用。
BladeDISC是什么
BladeDISC是阿里最新开源的基于MLIR的动态shape深度学习编译器。
主要特性
- 多款前端框架支持:TensorFlow,PyTorch
- 多后端硬件支持:CUDA,ROCM,x86
- 完备支持动态shape语义编译
- 支持推理及训练
- 轻量化API,对用户通用透明
- 支持插件模式嵌入宿主框架运行,以及独立部署模式
开源地址:
https://github.com/alibaba/BladeDISC
深度学习编译器的背景
近几年来,深度学习编译器作为一个较新的技术方向异常地活跃,包括老牌一些的TensorFlow XLA、TVM、Tensor Comprehension、Glow,到后来呼声很高的MLIR以及其不同领域的延伸项目IREE、mlir-hlo等等。能够看到不同的公司、社区在这个领域进行着大量的探索和推进。
AI浪潮与芯片浪潮共同催生——从萌芽之初到蓬勃发展
深度学习编译器近年来之所以能够受到持续的关注,主要来自于几个方面的原因:
框架性能优化在模型泛化性方面的需求
深度学习还在日新月异的发展之中,创新的应用领域不断涌现,复杂多变的场景下如何有效的将硬件的算力充分发挥出来成为了整个AI应用链路中非常重要的一环。在早期,神经网络部署的侧重点在于框架和算子库,这部分职责很大程度上由深度学习框架、硬件厂商提供的算子库、以及业务团队的手工优化工作来承担。
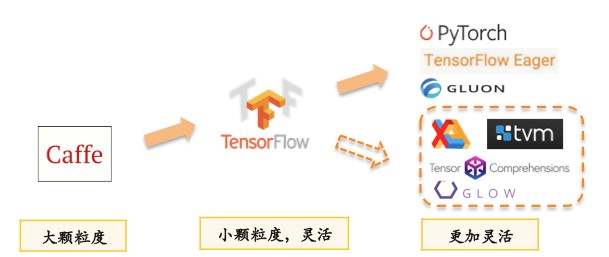
上图将近年的深度学习框架粗略分为三代。一个趋势是在上层的用户API层面,这些框架在变得越来越灵活,灵活性变强的同时也为底层性能问题提出了更大的挑战。初代深度学习框架类似 Caffe 用 sequence of layer 的方式描述神经网络结构,第二代类似 TensorFlow 用更细粒度的 graph of operators 描述计算图,到第三代类似 PyTorch,TensorFlow Eager Mode 的动态图。我们可以看到框架越来越灵活,描述能力越来越强,带来的问题是优化底层性能变得越来越困难。业务团队也经常需要补充完成所需要的手工优化,这些工作依赖于特定业务和对底层硬件的理解,耗费人力且难以泛化。而深度学习编译器则是结合编译时图层的优化以及自动或者半自动的代码生成,将手工优化的原理做泛化性的沉淀,以替代纯手工优化带来的各种问题,去解决深度学习框架的灵活性和性能之间的矛盾。
AI框架在硬件泛化性方面的需求
表面上看近些年AI发展的有目共睹、方兴未艾,而后台的硬件算力数十年的发展才是催化AI繁荣的核心动力。随着晶体管微缩面临的各种物理挑战越来越大,芯片算力的增加越来越难,摩尔定律面临失效,创新体系结构的各种DSA芯片迎来了一波热潮,传统的x86、ARM等都在不同的领域强化着自己的竞争力。硬件的百花齐放也为AI框架的发展带来了新的挑战。
而硬件的创新是一个问题,如何能把硬件的算力在真实的业务场景中发挥出来则是另外一个问题。新的AI硬件厂商不得不面临除了要在硬件上创新,还要在软件栈上做重度人力投入的问题。向下如何兼容硬件,成为了如今深度学习框架的核心难点之一,而兼容硬件这件事,则需要由编译器来解决。
AI系统平台对前端AI框架泛化性方面的需求
当今主流的深度学习框架包括Tensoflow、Pytorch、Keras、JAX等等,几个框架都有各自的优缺点,在上层对用户的接口方面风格各异,却同样面临硬件适配以及充分发挥硬件算力的问题。不同的团队常根据自己的建模场景和使用习惯来选择不同的框架,而云厂商或者平台方的性能优化工具和硬件适配方案则需要同时考虑不同的前端框架,甚至未来框架演进的需求。Google利用XLA同时支持TensorFlow和JAX,同时其它开源社区还演进出了Torch_XLA,Torch-MLIR这样的接入方案,这些接入方案目前虽然在易用性和成熟程度等方面还存在一些问题,却反应出AI系统层的工作对前端AI框架泛化性方面的需求和技术趋势。
什么是深度学习编译器
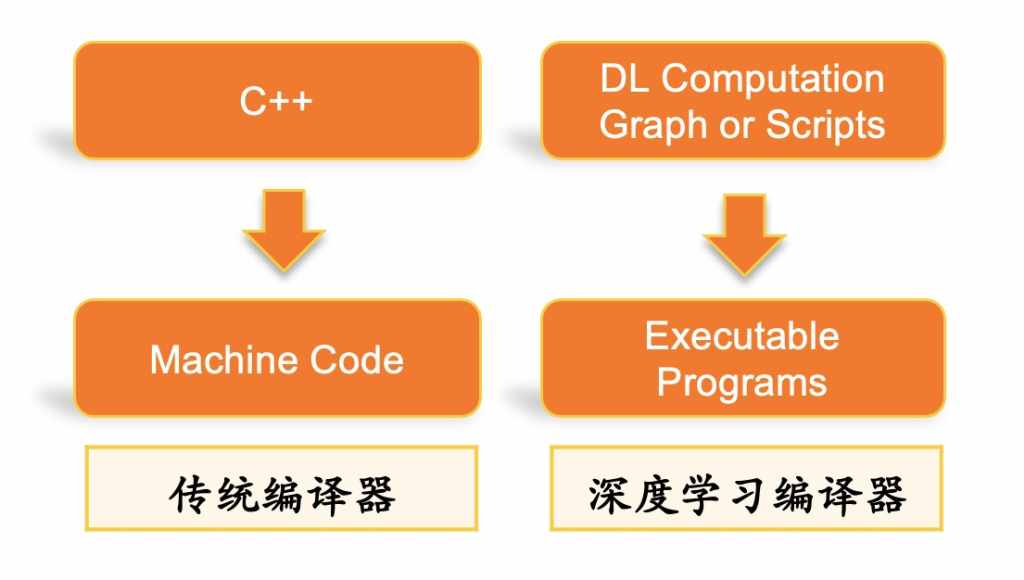
传统编译器是以高层语言作为输入,避免用户直接去写机器码,而用相对灵活高效的语言来工作,并在编译的过程中引入优化来解决高层语言引入的性能问题,平衡开发效率与性能之间的矛盾。而深度学习编译器的作用相仿,其输入是比较灵活的,具备较高抽象度的计算图描述,输出包括CPU、GPU及其他异构硬件平台上的底层机器码及执行引擎。
传统编译器的使命之一是减轻编程者的压力。作为编译器的输入的高级语言往往更多地是描述一个逻辑,为了便利编程者,高级语言的描述会更加抽象和灵活,至于这个逻辑在机器上是否能够高效的执行,往往是考验编译器的一个重要指标。深度学习作为一个近几年发展异常快速的应用领域,它的性能优化至关重要,并且同样存在高层描述的灵活性和抽象性与底层计算性能之间的矛盾,因此专门针对深度学习的编译器出现了。而传统编译器的另外一个重要使命是,需要保证编程者输入的高层语言能够执行在不同体系结构和指令集的硬件计算单元上,这一点也同样反应在深度学习编译器上。面对一个新的硬件设备,人工的话不太可能有精力对那么多目标硬件重新手写一个框架所需要的全部算子实现,深度学习编译器提供中间层的IR,将顶层框架的模型流图转化成中间层表示IR,在中间层IR上进行通用的图层优化,而在后端将优化后的IR通用性的生成各个目标平台的机器码。
深度学习编译器的目标是针对AI计算任务,以通用编译器的方式完成性能优化和硬件适配。让用户可以专注于上层模型开发,降低用户手工优化性能的人力开发成本,进一步压榨硬件性能空间。
距离大规模应用面临的瓶颈问题
深度学习编译器发展到今天,虽然在目标和技术架构方面与传统编译器有颇多相似之处,且在技术方向上表现出了良好的潜力,然而目前的实际应用范围却仍然距离传统编译器有一定的差距,主要难点包括:
易用性
深度学习编译器的初衷是希望简化手工优化性能和适配硬件的人力成本。然而在现阶段,大规模部署应用深度学习编译器的挑战仍然较大,能够将编译器用好的门槛较高,造成这个现象的主要原因包括:
- 与前端框架对接的问题。不同框架对深度学习任务的抽象描述和API接口各有不同,语义和机制上有各自的特点,且作为编译器输入的前端框架的算子类型数量呈开放性状态。如何在不保证所有算子被完整支持的情况下透明化的支持用户的计算图描述,是深度学习编译器能够易于为用户所广泛使用的重要因素之一。
- 动态shape问题和动态计算图问题。现阶段主流的深度学习编译器主要针对特定的静态shape输入完成编译,此外对包含control flow语义的动态计算图只能提供有限的支持或者完全不能够支持。而AI的应用场景却恰恰存在大量这一类的任务需求。这时只能人工将计算图改写为静态或者半静态的计算图,或者想办法将适合编译器的部分子图提取出来交给编译器。这无疑加重了应用深度学习编译器时的工程负担。更严重的问题是,很多任务类型并不能通过人工的改写来静态化,这导致这些情况下编译器完全无法实际应用。
- 编译开销问题。作为性能优化工具的深度学习编译器只有在其编译开销对比带来的性能收益有足够优势的情况下才真正具有实用价值。部分应用场景下对于编译开销的要求较高,例如普通规模的需要几天时间完成训练任务有可能无法接受几个小时的编译开销。对于应用工程师而言,使用编译器的情况下不能快速的完成模型的调试,也增加了开发和部署的难度和负担。
- 对用户透明性问题。部分AI编译器并非完全自动的编译工具,其性能表现比较依赖于用户提供的高层抽象的实现模版。主要是为算子开发工程师提供效率工具,降低用户人工调优各种算子实现的人力成本。但这也对使用者的算子开发经验和对硬件体系结构的熟悉程度提出了比较高的要求。此外,对于新硬件的软件开发者来说,现有的抽象却又常常无法足够描述创新的硬件体系结构上所需要的算子实现。需要对编译器架构足够熟悉的情况下对其进行二次开发甚至架构上的重构,门槛及开发负担仍然很高。
鲁棒性
目前主流的几个AI编译器项目大多数都还处于偏实验性质的产品,但产品的成熟度距离工业级应用有较大的差距。这里的鲁棒性包含是否能够顺利完成输入计算图的编译,计算结果的正确性,以及性能上避免coner case下的极端badcase等。
性能问题
编译器的优化本质上是将人工的优化方法,或者人力不易探究到的优化方法通过泛化性的沉淀和抽象,以有限的编译开销来替代手工优化的人力成本。然而如何沉淀和抽象的方法学是整个链路内最为本质也是最难的问题。深度学习编译器只有在性能上真正能够代替或者超过人工优化,或者真正能够起到大幅度降低人力成本作用的情况下才能真正发挥它的价值。
然而达到这一目标却并非易事,深度学习任务大都是tensor级别的计算,对于并行任务的拆分方式有很高的要求,但如何将手工的优化泛化性的沉淀在编译器技术内,避免编译开销爆炸以及分层之后不同层级之间优化的联动,仍然有更多的未知需要去探索和挖掘。这也成为以MLIR框架为代表的下一代深度学习编译器需要着重思考和解决的问题。
BladeDISC的主要技术特点
项目最早启动的初衷是为了解决XLA和TVM当前版本的静态shape限制,内部命名为 DISC (DynamIc Shape Compiler),希望打造一款能够在实际业务中使用的完备支持动态shape语义的深度学习编译器。
从团队四年前启动深度学习编译器方向的工作以来,动态shape问题一直是阻碍实际业务落地的严重问题之一。彼时,包括XLA在内的主流深度学习框架,都是基于静态shape语义的编译器框架。典型的方案是需要用户指定输入的shape,或是由编译器在运行时捕捉待编译子图的实际输入shape组合,并且为每一个输入shape组合生成一份编译结果。
静态shape编译器的优势显而易见,编译期完全已知静态shape信息的情况下,Compiler可以作出更好的优化决策并得到更好的CodeGen性能,同时也能够得到更好的显存/内存优化plan和调度执行plan。然而,其缺点也十分明显,具体包括:
- 大幅增加编译开销。引入离线编译预热过程,大幅增加推理任务部署过程复杂性;训练迭代速度不稳定甚至整体训练时间负优化。
- 部分业务场景shape变化范围趋于无穷的,导致编译缓存永远无法收敛,方案不可用。
- 内存显存占用的增加。编译缓存额外占用的内存显存,经常导致实际部署环境下的内存/显存OOM,直接阻碍业务的实际落地。
- 人工padding为静态shape等缓解性方案对用户不友好,大幅降低应用的通用性和透明性,影响迭代效率。

在2020年夏天,DISC完成了仅支持TensorFlow前端以及Nvidia GPU后端的初版,并且正式在阿里内部上线投入实际应用。最早在几个受困于动态shape问题已久的业务场景上投入使用,并且得到了预期中的效果。即在一次编译且不需要用户对计算图做特殊处理的情况下,完备支持动态shape语义,且性能几乎与静态shape编译器持平。对比TensorRT等基于手工算子库为主的优化框架,DISC基于编译器自动codegen的技术架构在经常为非标准开源模型的实际业务上获得了明显的性能和易用性优势。